ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs
1. SSE, CUHKSZ 2. Zhejiang University
Abstract
We present a novel approach, termed ADGaussian, for generalizable street scene reconstruction. The proposed method enables high-quality rendering from single-view input. Unlike prior Gaussian Splatting methods that primarily focus on geometry refinement, we emphasize the importance of joint optimization of image and depth features for accurate Gaussian prediction. To this end, we first incorporate sparse LiDAR depth as an additional input modality, formulating the Gaussian prediction process as a joint learning framework of visual information and geometric clue. Furthermore, we propose a multi-modal feature matching strategy coupled with a multi-scale Gaussian decoding model to enhance the joint refinement of multi-modal features, thereby enabling efficient multi-modal Gaussian learning. Extensive experiments on two large-scale autonomous driving datasets, Waymo and KITTI, demonstrate that our ADGaussian achieves state-of-the-art performance and exhibits superior zero-shot generalization capabilities in novel-view shifting.
Overview
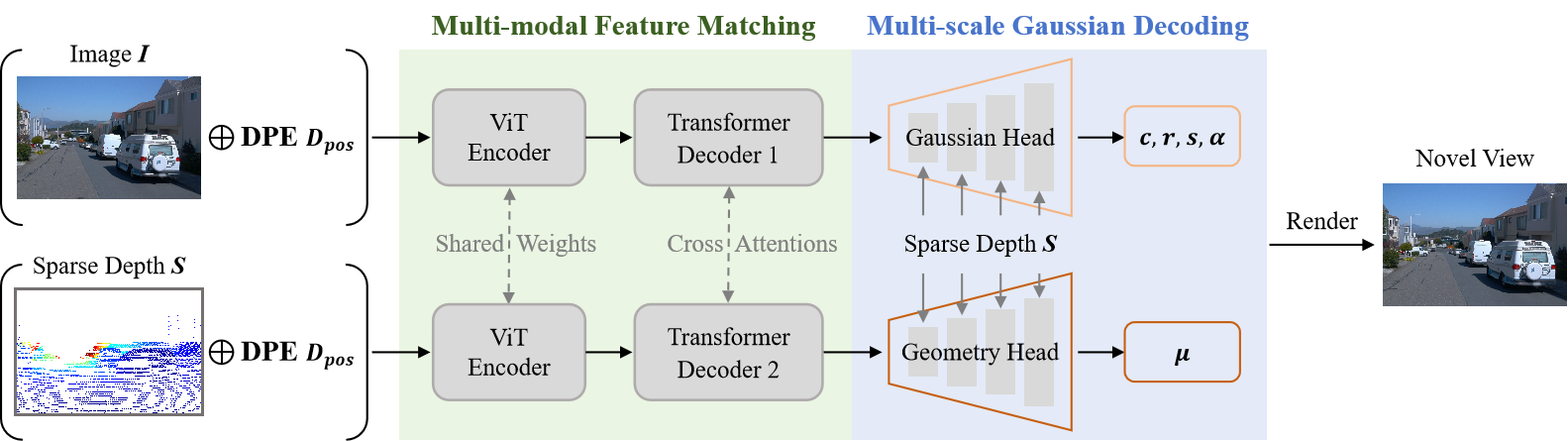
Given monocular posed image with sparse depth as input, ADGaussian first extracts well-fused multi-modal features through Multi-modal Feature Matching, which contains a siamese-style encoder and a cross-attention decoder enhanced by Depth-guided positional embedding (DPE). Subsequently, the Gaussian Head and Geometry Head, augmented with Multi-scale Gaussian Decoding, are utilized to predict different Gaussian parameters.
Comparison


Zero-shot large-view rendering video
The concept of novel-view shifting involves generating images from significantly varied perspectives compared to the original viewpoints present in the training data. We can evaluate the robustness on large viewpoint changes by applying the leftward and rightward view shifting.
We can also achieve the zero-shot left2right camera rendering on the KITTI dataset. Moreover, we can use the ground truth right camera images provided in the KITTI dataset to evaluate the quantitative performance of view shifting.