Envision4D: Envisioning Visual Futures via Feed-forward 4D Gaussian Splatting for Autonomous Driving
1. Tsinghua University 2. The Chinese University of Hong Kong, Shenzhen

Abstract
Forecasting the future evolution of dynamic scenes is crucial in autonomous driving. However, existing feed-forward paradigms are primarily designed for interpolation. When extended to future extrapolation, they suffer from ghosting artifacts under large displacements and are constrained by simplified motion assumptions or strict future priors. To overcome these challenges, we propose Envision4D, a fully self-supervised feed-forward framework for pose-free future extrapolation. Specifically, we introduce a Future Pose Prediction module that infers future camera parameters via an iterative denoising process. Furthermore, to capture non-linear dynamics, we propose In-layer Temporal Attention and employ Conditioned Motion Lifting, which transforms the highly uncertain extrapolation process into robust relational mappings. Finally, a Progressive Training Strategy is utilized to stabilize unsupervised motion learning against error accumulation. Extensive experiments demonstrate that Envision4D achieves state-of-the-art performance, significantly outperforming existing methods in future view synthesis.
Overview
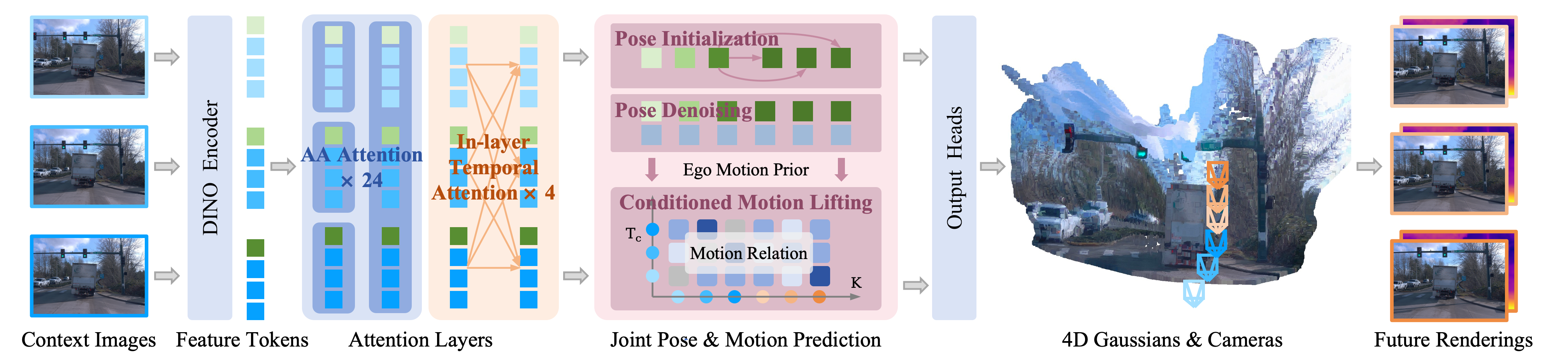
Given a sequence of context images, Envision4D predicts 4D Gaussians and all target camera poses. The motion awareness of feature tokens is first enhanced via In-layer Temporal Attention. Subsequently, Joint Pose-Motion Prediction is applied to enable future pose estimation through iterative denoising, alongside non-linear motion generation via conditioned motion lifting. The generated tokens are then decoded to render novel future views.
Comparison on Long-term Extrapolation
Unlike interpolation where motion errors are typically constrained between observations, extrapolation is highly ill-posed, with errors accumulating sharply as the number of extrapolated future frames increases. As analyzed in the table below, our method yields stable high-fidelity rendering across extended extrapolation horizons. Notably, our long-term prediction (Tf = 6) yields even higher PSNR and LPIPS quality than STORM's short-term output (Tf = 2), demonstrating exceptional robustness against temporal error accumulation. Additionally, extending context frames further enhances extrapolation capability by providing richer dynamic cues.
Quantitative comparison under varying context (Tc) and future (Tf) frames. Notably, our method at Tf = 6 even achieves competitive performance compared to STORM at Tf = 2.
| Tc | Tf | PSNR ↑ | SSIM ↑ | LPIPS ↓ | |||
|---|---|---|---|---|---|---|---|
| STORM | Ours | STORM | Ours | STORM | Ours | ||
| 2 | 2 | 26.19 | 27.81 | 0.798 | 0.816 | 0.242 | 0.159 |
| 2 | 4 | 25.55 | 26.87 | 0.773 | 0.790 | 0.263 | 0.170 |
| 2 | 6 | 24.41 | 26.21 | 0.753 | 0.771 | 0.346 | 0.192 |
| 3 | 6 | 24.62 | 26.46 | 0.752 | 0.782 | 0.302 | 0.187 |

Qualitative comparisons of long-term future extrapolation. The blue and orange dots denote the input observation frames and extrapolated future frames, respectively. The challenging dynamic objects are highlighted in red boxes across the input frames. It is noted that our model achieves significantly more stable and temporally consistent future extrapolation, even without extra motion guidance and ground-truth future poses.
Demo Video
Here are some demo videos. As can be seen, Envision4D achieves robust future extrapolation in dynamic scenarios, successfully breaking free from the constraints of extra explicit guidance and restrictive future priors.